Metoda gradientu sprzężonego
Metoda gradientu sprzężonego (ang. conjugate gradient method, w skrócie CG) jest algorytmem numerycznym służącym do rozwiązywania niektórych układów równań liniowych. Pozwala rozwiązać te, których macierz jest symetryczna i dodatnio określona. Metoda gradientu sprzężonego jest metodą iteracyjną, więc może być zastosowana do układów o rzadkich macierzach, które mogą być zbyt duże dla algorytmów bezpośrednich takich jak np. rozkład Choleskiego. Takie układy pojawiają się często w trakcie numerycznego rozwiązywania równań różniczkowych cząstkowych.
Metoda gradientu sprzężonego może również zostać użyta do rozwiązania problemu optymalizacji bez ograniczeń.
Opis metody
Rozpatrzmy rozwiązania poniższego układu równań:
- Ax = b,
gdzie macierz A n na n jest symetryczna, rzeczywista i dodatnio określona.
Oznaczmy rozwiązanie tego układu przez x*.
Bezpośrednia metoda gradientu sprzężonego
Mówimy, że dwa niezerowe wektory u i v są sprzężone (względem A), jeśli

Ponieważ A jest symetryczna i dodatnio określona, lewa strona definiuje iloczyn skalarny:

Więc, dwa wektory są sprzężone jeśli są ortogonalne względem tego iloczynu skalarnego. Sprzężoność jest relacją symetryczną.
Przypuśćmy, że {pk} jest ciągiem n wzajemnie sprzężonych kierunków. Wtedy pk tworzą bazę Rn, wektor x* będący rozwiązaniem Ax = b możemy przedstawić w postaci:

Współczynniki otrzymujemy w następujący sposób:



Co daje nam następującą metodę rozwiązywania równania Ax = b. Najpierw znajdujemy ciąg n sprzężonych kierunków, następnie obliczamy współczynniki

Metoda gradientu sprzężonego jako metoda iteracyjna
Jeśli właściwie dobierzemy sprzężone wektory pk, możemy nie potrzebować ich wszystkich do dobrej aproksymacji rozwiązania x*. Możemy więc spojrzeć na CG jak na metodę iteracyjną. Co więcej, pozwoli nam to rozwiązać układy równań, gdzie n jest tak duże, że bezpośrednia metoda zabrałaby zbyt dużo czasu.
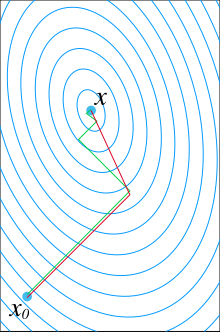
Oznaczmy punkt startowy przez x0. Bez starty ogólności możemy założyć, że x0 = 0 (w przeciwnym przypadku, rozważymy układ Az = b − Ax0). Zauważmy, że rozwiązanie x* minimalizuje formę kwadratową:

Co sugeruje, by jako pierwszy wektor bazowy p1 wybrać gradient f w x = x0, który wynosi Ax0−b, a ponieważ wybraliśmy x0 = 0, otrzymujemy −b. Pozostałe wektory w bazie będą sprzężone do gradientu (stąd nazwa metoda gradientu sprzężonego).
Niech rk oznacza rezyduum w k-tym kroku:

Zauważmy, że rk jest przeciwny do gradientu f w x = xk, więc metoda gradientu prostego nakazywałaby ruch w kierunku rk. Tutaj jednak założyliśmy wzajemną sprzężoność kierunków pk, więc wybieramy kierunek najbliższy do rk pod warunkiem sprzężoności. Co wyraża się wzorem:

Wynikowy algorytm
Upraszczając, otrzymujemy poniższy algorytm rozwiązujący Ax = b, gdzie macierz A jest rzeczywista, symetryczna i dodatnio określona. x0 jest punktem startowym.
- repeat
- if rk+1 jest "wystarczająco mały" then exit loop end if
- end repeat
- Wynikiem jest










Przykład metody gradientu sprzężonego w Octave/MATLAB
function [x] = conjgrad(A,b,x0) r = b - A*x0; w = -r; z = A*w; a = (r'*w)/(w'*z); x = x0 + a*w; for i = 1:size(A,1); r = r - a*z; if( norm(r) < 1e-10 ) break; end B = (r'*z)/(w'*z); w = -r + B*w; z = A*w; a = (r'*w)/(w'*z); x = x + a*w; end end
Zobacz też
- metoda gradientu prostego
- metoda najszybszego spadku
- metoda Newtona
- metoda złotego podziału
- optymalizacja
Bibliografia
- Metoda gradientu sprzężonego została zaproponowana w:
- Magnus R.M.R. Hestenes Magnus R.M.R., EduardE. Stiefel EduardE., Methods of Conjugate Gradients for Solving Linear Systems [PDF], „Journal of Research of the National Bureau of Standards”, 6, 49, grudzień 1952 [dostęp 2009-01-20] [zarchiwizowane z adresu 2010-05-05] .
- Opisy meteody można znaleźć w:
- Kendell A. Atkinson (1988), An introduction to numerical analysis (2nd ed.), Section 8.9, John Wiley and Sons. ISBN 0-471-50023-2.
- Mordecai Avriel (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 0-486-43227-0.
- Gene H. Golub and Charles F. Van Loan, Matrix computations (3rd ed.), Chapter 10, Johns Hopkins University Press. ISBN 0-8018-5414-8.
Linki zewnętrzne
- Conjugate Gradient Method by Nadir Soualem.
- Preconditioned conjugate gradient method by Nadir Soualem.
- An Introduction to the Conjugate Gradient Method Without the Agonizing Pain by Jonathan Richard Shewchuk.
- Iterative methods for sparse linear systems by Yousef Saad
- LSQR: Sparse Equations and Least Squares by Christopher Paige and Michael Saunders.









